An Overview of Bandits

In this post, we will take a look at the bandit problem and discuss some solution strategies. This is a fairly introductory overview so a basic understanding of probability should be enough to get through this one. Most of the posts on my page talk about RL and various topics related to RL and this post is no different. If you are already familiar with some RL, then the best way to understand bandits is as a simplified RL problem. If you aren’t familiar with RL, we’ll start from scratch anyway and try to make the link with RL at the end of this post. And with that, lets begin.
What are Bandits?

Multi-armed bandits or bandits are like a slot machine. An arm of a bandit is like the lever of the slot machine that you pull to get some sort of reward or payoff. So imagine now that there is a slot machine with multiple arms. Each arm has an asociated probability distribution of the payoff that it might give. For simplicity, let us assume all of those distributions are Bernoulli distributions for now (although they may be any distribution). So every time you pull an arm a, you get a payoff 1 with probability p and 0 with probability 1-p. Now every arm has a similar Bernoulli reward distribution with different p values. If you are familiar with the Bernoulli distribution and how to calculate expectations, you’ll quickly realize that the expected payoff for arm a is p. Our job is to find and play the arm that would give us the maximum payoff. Now if we knew the distribution associated with each arm and hence the expected payoff for each arm, this would be a trivial problem. All we have to do is keep playing the arm with the highest expected payoff and this is the best we can do (in the Bernoulli case, this will be the arm with the highest probability of giving us a payoff of one). But the catch is that we do not know the distributions associated with each arm. Now, how do we solve the problem?
Stationary and Non-stationary bandit problems
Before we start talking about the possible solution strategies for the bandit problem, I’d like to quickly point out the distinction between stationary bandits and non-stationary bandits. We spoke about each arm having an associated probability distribution for giving out rewards. If this probability distribution is fixed over time, we call it a stationary bandit problem. If it changes over time, we call it a non-stationary bandit problem. In this post, we will only talk about stationary bandits and their solutions. In fact, many of the solutions to the stationary bandit problem can be adapted for the non-stationary case as well but we will not deal with them here.
Solution Strategies
Note: Unless otherwise specified, we will stick to Bernoulli bandits for the sake of simplicity.
The Naive Solution
You’ve probably already thought of it by now but the easiest solution to the problem is to pull each arm many, many times and using the law of large numbers, estimate the expected payoff of each arm and then keep playing the arm with maximum payoff. This will work but it will take a long time and several arm pulls to get a good estimate of the expected payoff so this is inefficient. How can we do better?
Before we get into some more intricate solutions, we will need a little bit more background. From now on, we will refer to the true expected payoff of arm a as q*(a) and the expected payoff for arm a that we have computed as q(a). So in our initial example, q*(a) = p, but we do not know this value or any other q*(a) value. We only know the q values which are our estimates of the true q*(a) values and we want to get our estimates as accurate as possible so that we can eventually pick and play the best arm all the time. One simple example of finding q values is by taking an average reward obtained from each arm (in the Bernoulli case this will be between 0 and 1).
So its quite clear that our naive solution is inadequate to solve the problem. Is there even another way? As it turns out, there is. We don’t want to play so many arms before we find the best arm, so we need to be smart about which arms we want to play and when. Bandit algorithms and RL algorithms as well follow this extremely crucial strategy called the exploration-exploitation strategy. The idea now is to explore all the arms of the bandit to try and get an idea of their reward distributions whilst also exploting the information we have by playing the arm with the maximum q value. This is the expore-exploit dilemma that algorithms must handle. We want to explore as many arms as possible while trying to increase our payoff by playing the best possible arm (according to us, at the time). Now there are several clever exploration strategies that we will talk about in this post but the idea behind all of them is the same. Why can’t we just constantly exploit? This would be fine if the best arm according to us is the true best arm, but if we’re wrong, then we will constantly play a sub-optimal arm and never learn to play the best arm. Hence, exploration is crucial and you will find that smart exploration will help us find the best arm much faster than our previous naive solution.
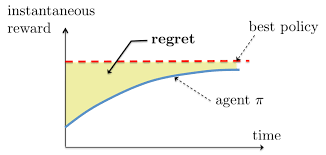
We are going to define a new term now called regret. Lets assume that we will be able to eventually solve the bandit problem and start playing the right arm all the time. In fact, we have already seen a simple solution to do it and we have spoken about how exploration can improve that solution. The only question is, when? The sooner we find the best arm, the better our bandit algorithm is. We just spoke about the importance of exploration and how it is going to help us find the best arm quickly. There are several different ways to explore and some strategies take us very close to the optimal payoff very quickly but take a long time to reach the optimal payoff. Some other strategies may increase the payoff slowly but eventually reach the optimal payoff faster than the former strategy. In either case, the diagram of how the reward we get increases with time is as follows. The curve itself could be steeper or flatter but the shape is similar. The policy $\pi$ is nothing but a mapping of actions to the probability of playing that action. So $\pi_{t}(a)$ is the probability of playing action a. The policy is subscripted with t because it changes with time. Regret, the region shown in the diagram, is the additional reward you could have gained if you had known the best arm from the very beginning. One of the key goals of bandit algorithms is to minimize regret. At any time t, the regret at the time is proportional to $logt$ but we can play around with the constant (in other words, $logt$ is the lower bound).
Epsilon-greedy exploration and Softmax Exploration
Lets begin with a simple exploration policy. $\epsilon$-greedy exploration is the simplest exploration policy but is also very important because it is used a lot in the full RL problem as well. It says be greedy and pick the best arm with probability $1-\epsilon$ and pick a random arm (from all the arms including the best arm) with probability $\epsilon$. But we don’t want to constantly explore. To eventually converge to the best arm, we need to stop exploring. A good idea is to start with a “high” (perhaps close to 1) value of $\epsilon$ and keep reducing at the rate of $1/t$ where t is time.
But we have a problem with this strategy. If we know after a point that some arms are terrible, we don’t want to keep playing them. Also if we have an arm with a slightly higher q value than the second best arm, the second best arm is weighted equally with all the other inferior arms. We may want to explore that second best arm a little more to make sure it isn’t the best arm. All this is a long preamble to say that we want to weight our exploration by the q-value of the arm. We can do this by picking arm a at time t with probability as follows (assume multi-armed bandit with n arms):
$$\frac{q_{t}(a)}{\sum_{b=1}^{n} q_{t}(b)}$$
But the problem here is that the numerator can be negative and hence the probabilities can be negative. We fix this by using the following formulation. This is called softmax exploration.
$$\frac{e^{q_{t}(a)/\beta}}{\sum_{b=1}^{n} e^{q_{t}(b)/\beta}}$$
$\beta$ is called the temperature parameter and if it is very high, the exploration is completely random. So we start with a high $\beta$ value and keep cooling down and then as $\beta$ tends to 0, we have just the argmax formulation.
Both these strategies are used even in the full RL problem. Both these strategies also require us to keep track of the running sum of the q-values. This equation, which is a form of a stochastic averaging equation does just that. It is fairly straight-forward to derive.
$$q_t(a) = q_{t-1}(a) + \frac{1}{n_a+1}(r_t - q_{t-1}(a))$$
Here, $r_t$ is the reward we obtained for playing arm a at time t and $n_a$ is the number of times we have played arm a excluding the current play (the +1 is for the current play).
UCB1
UCB stands for Upper Confidence Bound. This strategy is supposed to have some good regret bounds. The algorithm is straight-forward and is presented below.
Initialisation: Play each arm once.
Loop: Pull arm j that maximises:
$$q(j) + 2 \sqrt{\frac{\ln{n}}{n_j}}$$
Here, n is the total number of arm plays and $n_j$ is the total number of plays of arm j. $q_j$ is the expected payoff at time n for arm j. Note that this only works for q values bound between 0 and 1. If they are not, then rescale them.
There is a UCB theorem that proves the correctness of the algorithm and how we obtain that magic number in the square root. But I will not get into the proof here. I will give a little bit of intuition though. We want to pick the arm that maximises the q-value but what is the term in the square root? It is like a confidence bound. UCB says that it isn’t just going to use the q vaues but since it has drawn many samples, it is going to use that information as well to tell what is the confidence with which it can make that estimate. It kind of gives a bound around the q value. If we have more samples, the bound reduces and as the number of samples tend to infinity, the q values tend to the true values. So the idea of UCB is to take not just the arm with the max q value but also the one with the widest range of possible values i.e. the highest upper confidence bound. It also says that since this bound is very big, the arm hasn’t been played enough.
But without going into any of these details, it is a very simple algorithm to implement and get some very good results.
Naive PAC
PAC stands for Probably Approximately Correct and often comes with a tag such as $(\epsilon, \delta)$-PAC which means our algorithm will take in input values $\epsilon$ and $\delta$ and give out an arm that satisfies the condition that with probability $1-\delta$, the expected payoff is $\epsilon$ within the best arm.
The naive PAC algorithm is as follows:
for each arm 'a' do:
sample 'a' 'l' times
Let q(a) be the average reward of arm 'a'
Output a with the max q(a) value
Here the magic number ‘l’ is given as (where K is the number of arms): $$l = \frac{2}{\epsilon^2} \ln(\frac{2K}{\delta})$$
Once again, the algorithm is extremely easy to implement and the only question is how we got the magic number ‘l’. There is a theorem that derives this and proves the sample complexity of the algorithm but I will not get into the details here.
Median Elimination PAC
This is another PAC algorithm that is as follows. Once again, the algorithm is very easy to implement but much harder to prove so we will not get into the details here.

A is the set of all arms. Median elimination proceeds in rounds. In each round, pull each arm the magic number times. Once we have done that, find the median of all the q values. Then eliminate all arms whose value is less than the median. Again, change the constants by some magic numbers. Keep going until we have only one arm left.
Other Solution strategies
We will quickly talk about a few more solution strategies for the bandit problem. The first one is Thompson Sampling which is like a Bayesian treatment of the problem. This method is supposed to get better regret bounds than UCB. It involves guessing probability distributions of the different q* values and eventually narrowing down these distributions until they converge.
The next one is called Policy Search. As we already mentioned, a policy is a mapping from states to actions in the full RL problem but since we have no states here, it will just be the probability of picking each action at different timesteps. So we represent a policy as $\pi_t(a)$. Now we don’t try and find any value functions anymore. We update the policy directly with certain algorithms like Linear Reward Penalty algorithm, Linear Reward $\epsilon$-penalty algorithm and Linear Reward Inaction algorithm. Each of them have very different convergence behaviours and are suitable for different kinds of bandit problems.
Another common approach that we see a lot in the full RL problem as well is the Policy Gradient technique where once again, we update the parameters of a policy directly without calculating any intermediate value functions. What do we mean by parameters of a policy? A policy is a probability distribution and we can represent this in many ways, for example, as a softmax function. The exponent in the softmax function can be “anything” and this “anything” can involve some parameters that we want to optimise to learn the ideal policy. These parameteres are also called preferences. The parameters often come from a neural network. We won’t talk about policy gradients too much here and we will deal with it in detail in the context of the full RL problem (in the RL course on my page).
Contextual Bandits – A Step Towards the Full RL problem
We now relax the bandit assumption of “no states” and we take a step towards the full RL problem. In fact, the bandit problem is called Immediate RL because as soon as we play the action, we get the feedback in the form of a reward. So contextual bandits are between immediate RL and the full RL problem. But RL problems have a certain sequential dependence that we don’t have in the contextual bandit case. This means we don’t need to learn the best sequence of states and actions as we do in the full RL problem; the actions we pick now won’t affect our future and we don’t care about the sequence of actions in our past. All we need to do is pick the best action in each state. So this can be thought of as solving many bandit problems. So if we have 10 states, we have 10 bandit problems and we can solve each of them. These problems are often solved by parametrisation of the states, the actions and the policy (although in many cases this means we parameterise the value function and not the policy).
And with that we have covered the bandit problem and some of its solutions. Now that we’ve gone through all of that, it may be worth it to look at some real-world applications of bandits. You can find some in the paper I have linked below.
Let me know if you have any suggestions/if I have made any mistakes!
References
Skanda Vaidyanath
Member of Technical Staff
My research interests lie primarily in the area of reinforcement learning (RL) and control to build agents that can acquire complex behaviours in the real world via interaction.