Bridging the Gaps With Reinforcement Learning

In this post, I will be talking about a unique way to use reinforcement learning (RL) in deep learning applications. I definitely recommend brushing up some deep learning fundamentals and if possible, some policy gradient fundamentals as well before you get started with this post.
Traditionally, RL is used to solve sequential decision making problems in the video game space or robotics space or any other space where there is a concrete RL task at hand. There are several applications in the fields of video games and robotics where the task at hand can be very easily seen as an RL problem and can be modeled appropriately as well. But RL as a technique is quite versatile and can be used in several other domains to train neural networks that are traditionally trained in a supervised fashion. We’ll talk about one very important such application in this post. Along the way, I’ll also try to convince you that this isn’t really a different way to use RL but rather just a different way to look at the traditional RL problem. So with that, lets begin!
Non-differentiable steps in deep learning: The Gaps
Sometimes when we’re coming up with neural network architectures, we may need to incorporate some non-differentiable operations as a part of our network. Now this is a problem as we can’t backpropagate losses through such operation and hence lets call these “gaps”. So what are some common gaps we come across in neural networks?
On a side-note, before we start talking about some “real gaps”, its worth mentioning that the famous ReLU function is a non-differentiable function but we overcome that gap by setting the derivative at 0 to either 1 or 0 and get away with it.
Now lets take a better example – variational autoencoders (VAE). Without going into two many details, the VAE network outputs two vectors: a $\mu$ vector and a $\sigma$ vector and it involves a crucial sampling step where we sample from the distribution N($\mu$, $\sigma$) as a part of the network. Now sampling is a gap as it is a non-differentiable step. You should stop here and convince yourself that this is, in fact true. When we sample, we don’t know what the outcome will be and hence the function in not differentiable. So how do they get over this in the VAE case? They use a clever trick. Instead of sampling from N($\mu$, $\sigma$), they just rewrite this as $\mu$ + $\sigma$N(0,1) where they sample from the standard normal function. This neat trick now makes the expression differentiable because we just need the $\mu$ and $\sigma$ quantities to be differentiable and we don’t care about the N(0,1). Remember that we only need to differentiate with respect to the parameters of our network (brush up some backpropagation basics if you’re confused here) and hence we need to differentiate only with respect to $\mu$ and $\sigma$ and not the standard normal distribution. For more details about VAEs read this post or this one.
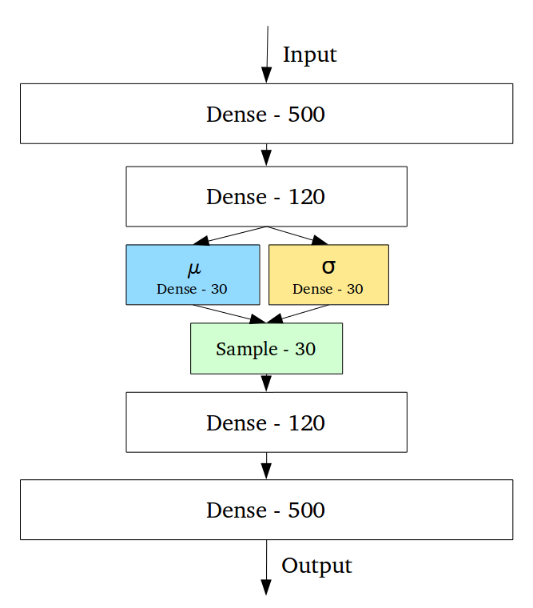
So as it turned out, that wasn’t a very good example either but we’re starting to understand what we mean by gaps now and how common they are. Some common examples of gaps in networks are sampling operations and the argmax operation. Once again, convince yourself that argmax is not a differentiable function. Assume you have a function that takes argmax of two quantities (x1,x2). When x1 > x2, this has value 0 (zero-indexed) and when x1 < x2, it has value 1. Say the function is not defined on the x1==x2 line or define it as you wish (0 or 1). Now if you can visualise the 2D plane, you’ll see that the function is not differentiable as we move across the x1==x2 line. So argmax isn’t differentiable but max is a differentiable function (recall max pooling in CNNs). Read this thread for more details.
These functions are commonly used in natural language processing (NLP) applications, information retrieval (IR) applications and Computer Vision (CV) applications as well. For example, a sampling function could be used to select words from a sentence based on a probability distribution in an NLP application or an argmax function could be used to find the highest ranked document in an IR application. Hard attention uses sampling techniques which involves non-differentiable computation.
So its quite clear that these gaps are common in several deep learning architectures and sometimes, it could even be useful to introduce such a gap in the network intentionally to reap added benefits. The only question is, how do we bridge these gaps?
Reinforcement Learning and Policy Gradients: The Bridge
Policy gradients are a class of algorithms in RL. There are several policy gradient algorithms and this is a great blog that lists out almost all of them. But without going into too many details, these algorithms work in the policy space by updating the parameters of the policy we’re trying to learn. That means we don’t necessarily need to find the value function of different states but we can directly alter our policy until we’re happy. The most common policy gradient (PG) algorithm is the REINFORCE which is a Monte Carlo algorithm. This means we run an entire episode and make changes to our policy only at the end of each episode and not at every step. We make these changes based on the returns that we received by taking a given action from a given state in the episode. I skip the derivation of the policy gradient here but it can be found in the link above. The final result is in the image below.
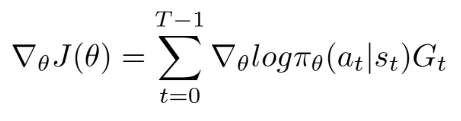
The key idea here is that in policy gradient methods, we are allowed to sample different actions from a given state and wait till the end of an episode before we make updates to our network. So if we have a sampling operation as a part of our network, we can introduce a policy gradient and think of it as sampling actions in a given state in an RL framework. A similar procedure can also be followed if we had argmax in place of the sampling operation.
Consider a neural network now with a gap. The images below are taken from this blog on Policy Gradients written by Andrej Karpathy.

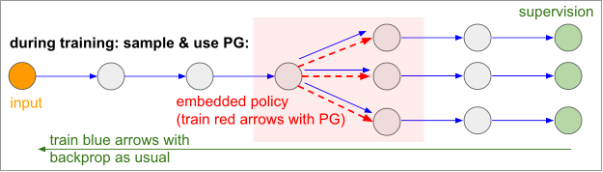
So now we can train the blue arrows i.e. the differentiable path as usual. But to train the red arrows, we need to introduce a policy gradient and as we sample, we ensure with the help of the policy gradient that we encourage samples that led to a lower loss. In this way, we are “training” the sampling operation or one could say, propagating the loss through the sampling operation! Note that the updates to the red arrows happen independently than those of the blue arrows. Note that in the diagrams above, there isn’t really a gap per-say because the blue arrows go all the way from start to finish. So there is a differentiable path and a non-differentiable path. A true gap would mean there would be no completely differentiable path at all. In this case, we need to make sure that the loss functions on either side of the gap are “in sync” and are being optimized in such a way that it facilitates joint training and achieves a common goal. This is often not as easy as it sounds.
I said at the start that as obscure as it seems, this is still the traditional RL problem we’re used to with the MDP and states and actions. We can still look at this entire setup as a traditional RL problem if we think of the inputs to the neural network as the state and the sampling process as sampling different actions from that given state. Now what is the reward function? This depends on what comes after the gap and could be an output from the rest of the network or it could be a completely independent reward function that you came up with as well. So at the end of the day, it is still the same MDP with the traditional setup but just used in a very different way.
Skanda Vaidyanath
Member of Technical Staff
My research interests lie primarily in the area of reinforcement learning (RL) and control to build agents that can acquire complex behaviours in the real world via interaction.