Introduction: Why RL?
Hi and welcome to the first post of this RL course! In this post, my aim will be to introduce the idea of RL to you and talk about the problems it solves and why it is important.
Reinforcement learning is like that little-known cousin of supervised learning and unsupervised learning. Or at least it was for the longest time. RL has actually been around a really long time and I would highly recommend reading the RL book for a more detailed account on the history of RL. But in recent times, its been gaining a lot of attention, mainly due to the conquests of DeepMind’s AlphaZero.
But having said that, people still don’t quite know what RL is yet and don’t know how and when to use it. So as a part of this introductory blog, I will try to answer three questions that are often asked about RL.
- What is Reinforcement Learning?
- How is it different from Supervised learning or Unsupervised learning?
- What problems can it solve?
And lets begin!
What is Reinforcement Learning?
Reinforcement learning is a paradigm of Machine Learning (ML). The most general way to divide ML into three parts would be as Supervised learning (SL), Unsupervised learning (USL) and Reinforcement Learning. But most people only talk about SL and USL when they talk about ML. So my first job is to explain why the third paradigm is important and how it is different from the first two.
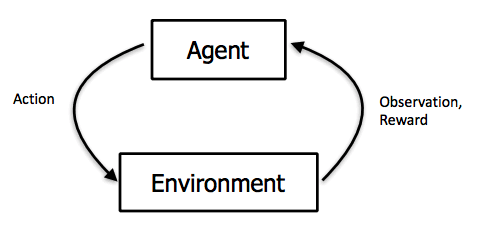
Reinforcement learning is an area of machine learning concerned with how software agents ought to take actions in an environment in order to maximize some notion of cumulative reward.
The above definition is taken from Wikipedia. The definition speaks about “agents” taking “actions” in “environments” to maximize “rewards”. But what does all this mean? Lets break it down, but before that, here is a simpler definition.
Reinforcement learning is simply learning by trial and error.
Think about how you started learning to ride a bike. You probably tried many different things (turning the handle-bar in different directions, trying to pedal backwards) and continued doing more of what worked (“worked” in this context probably means “did not fall and moved in the intended direction”) and less of what didn’t. Nobody gave you clear instructions on what to do at each step, you just tried things and they worked (or didn’t). In fact, humans gain several skills in the same fashion. Imagine you’re playing a brand new video game without reading the instructions or picking up a new sport. Humans learn several tasks by trial and error and that’s exactly what we’re trying to emulate with RL. Trying to get as close as possible to the way humans learn.

With that intuition, lets take a jab at the Wikipedia definition again. The “agent” in our biker example is the person trying to learn to ride a bike. The “environment” is everything that may affect the person riding the bike – so this could be the road, the traffic, the weather, etc. Remember the environment is dynamic – the traffic could get heavier, the weather could get rainier, etc. So the agent has to account for the different settings of the environment. As for “actions”, these are the different decisions the agent can make – for example, they could be “turn left”, “turn right”, etc. The agent must decide based on the state of the environment, what the right action to play is at a given point. And finally “rewards” is some sort of feedback we get for the series (could be singular) of actions we just took. So we would get a positive reward if we reached our destination and negative if we fell down for example. All these terms will be dealt with more formally in the next post. For now, just make sure you get the intuition.
So we have an agent that is going to try and take different possible actions in its environment (which is dynamic!) and learn the best actions under each setting of the environment in order to maximise some notion of a cumulative reward (a feedback signal). All this will get clearer as we go along but for now just remember this.
Bottomline: RL is just learning by trial and error to pick the right actions depending on the state of the environment.
How is it different from Supervised learning or Unsupervised learning?
This is the question I get asked the most about RL. The difference between RL and USL is quite clear. In USL, there is absolutely no form of feedback or supervision whereas in RL we do get some sort of feedback in the form of a reward signal. Hence, USL is often about finding some sort of structure or patterns in data with absolutely no supervision or feedback. This is not what we’re dealing with here.
So Reinforcement Learning is not Unsupervised learning.
The more pertinent question is – how is it different from supervised learning? Is RL just SL with class labels given in a different manner?
Lets look at another very common example. We want to teach our computer to play Tic Tac Toe.
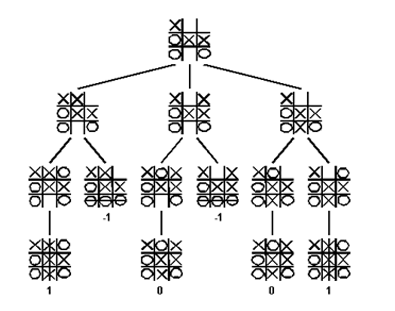
Our data is in the form of several games that have been played from start to finish. If we consider this as training data for our SL model, the only labels we could possibly decipher from these games would be the final outcome – the winner of the game or if it was a draw. If we are able to somehow encode the game and train a classifier on the data, this SL model would be able to predict the outcome of a game (which is not very useful) but not how to play the game. Stop for a second, think about all the different potential SL solutions to this problem and convince yourself that this would be an extremely difficult (if even possible) problem to solve if we do not have supervised labels telling us what the best move is for every board position.
If we wanted to train a SL model to learn how to play the game, we would need training data in the form of the best move to play at every board position. But alas, we do not have such information and this is the case in most problems (think about riding a cycle or playing chess or a video game).
So how does RL solve the problem? Think of the Tic Tac Toe board and the opponent as an environment now (we can convert our series of game descriptions to such a setup) and our agent is trying to learn how to play the game. If we have enough game descriptions or if the agent can experiment by trying different moves in different board positions through trial and error and observes the final outcome, then the agent can learn the best moves in the different positions! We’ll look into how exactly this is possible over the next couple of posts.
But since our aim was just to show that RL and SL are not the same, we are done here. SL requires “step-wise” (this is not a technical term and hence is in quotes, but you get the idea) labels to learn how to do a task. It requires “strong” supervision. RL can do the same thing with some sort of “weak”/“distant”/“semi”-supervision.
So Reinforcement Learning is not Supervised learning either.
What problems can it solve?
All this sounds great but what problems can RL solve? So far we’ve spoken about riding bikes and playing chess and video games but are there any significant real-world problems RL can solve?
As it turns out there are several. RL is also commonly referred to as Sequential Decision Making or Decision Making under Uncertainty or learning through Interactions. This makes it abundantly clear as to why it is not the same as SL or USL. There is no interaction or sequential decision making in SL or USL. There is a need for a paradigm that learns through interactions and not direct class labels in “uncertain” conditions. When we put it this way, we can think of several applications for RL in the real-world. I’ll talk about a few here.

RL gained massive popularity because of Google DeepMind and its success at playing Go and Chess and Atari Games as well but there are several other applications of RL.
RL is extremely versatile and can be used along with several other common ML areas like Computer Vision (CV) and Natural Language Processing (NLP).
The best example of using RL with CV is probably self-driving cars. With NLP, it can be used in dialogue systems. Another massive application area is in robotics and control. It can be used to train multi-agent systems, for example, a swarm of drones communicating with each other. One of my favourite applications of RL is personalized learning where an RL agent can design an optimal course for a student with the right number of tests/assignments administered at the right time to encourage maximum learning. There is similar work being done on personalized healthcare as well.

And so there are a ton of different applications that leverage the power of RL. There are also other slightly different uses, for example, RL can be used to overcome non-differentiable steps in deep learning.
And with that, we’ve answered all the questions that we set out to! We get into a lot more details in the next post so make sure you take a look at that as well.
Feel free to let me know if you have any feedback!